Qu'est-ce qui Détermine la Vitesse d'un Programme ?
- Introduction : Un problème multifactoriel
- L’algorithme : la base de la performance
- Langage : compilé vs interprété
- Accès mémoire : RAM, cache, disque
- Parallélisation : plus de cœurs ≠ plus vite
- Calcul GPU : des muscles, mais peu de souplesse
- Un mot sur le hardware
- Conclusion : comprendre avant d’optimiser
- Pour aller plus loin
Introduction : Un problème multifactoriel
Pourquoi un programme est-il lent ? Pourquoi un autre, parfois plus complexe, s’exécute pourtant bien plus rapidement ?
La performance d’un programme ne dépend pas d’un seul facteur, mais d’une chaîne complète allant du code jusqu’au matériel.
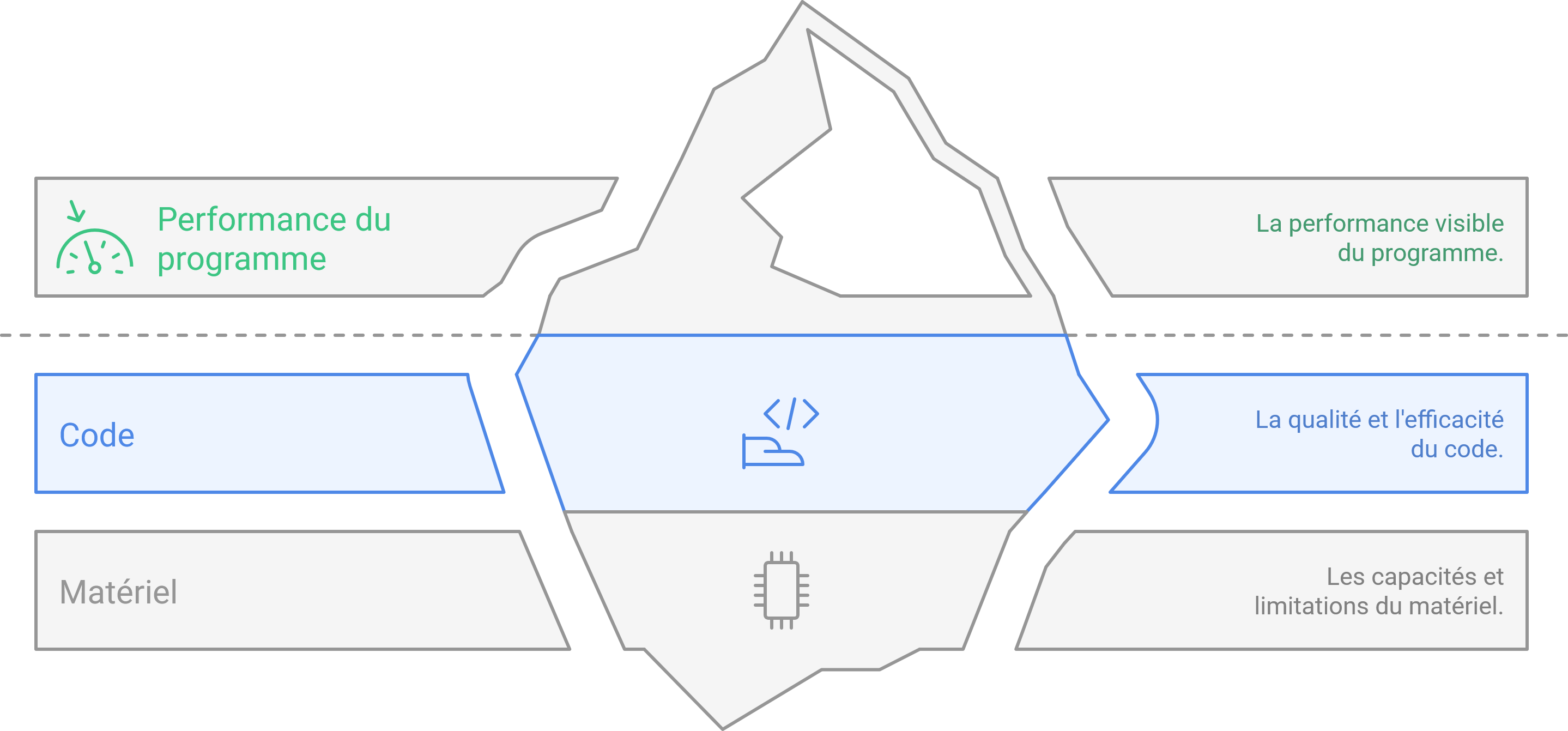
Ce billet de blog technique explore les multiples facettes qui influencent la vitesse d’exécution d’un programme. De l’algorithme fondamental à l’architecture matérielle sous-jacente, nous examinerons comment chaque composant contribue à la performance globale. L’objectif est de fournir une vue d’ensemble des principaux leviers d’optimisation, illustrés par des exemples concrets, afin de mieux comprendre et améliorer l’efficacité de vos programmes.
L’algorithme : la base de la performance
L’algorithme utilisé influe plus que n’importe quelle optimisation locale. Sa complexité algorithmique dicte le comportement de votre programme à grande échelle.
La complexité
La complexité algorithmique décrit comment le temps d’exécution (ou la mémoire utilisée) d’un programme évolue en fonction de la taille des données en entrée. Elle s’écrit souvent avec la notation O, qui donne un ordre de grandeur :
O(1)signifie que le temps est constant (indépendant de la taille),O(n)est linéaire (proportionnel à la taille des données),O(n²)devient vite coûteux (comme le tri à bulles),O(log n)ouO(n log n)sont typiques des algorithmes efficaces.
Cette mesure permet d’estimer la scalabilité d’un algorithme : un programme rapide sur 100 données peut devenir inutilisable sur 1 million si sa complexité est trop élevée.
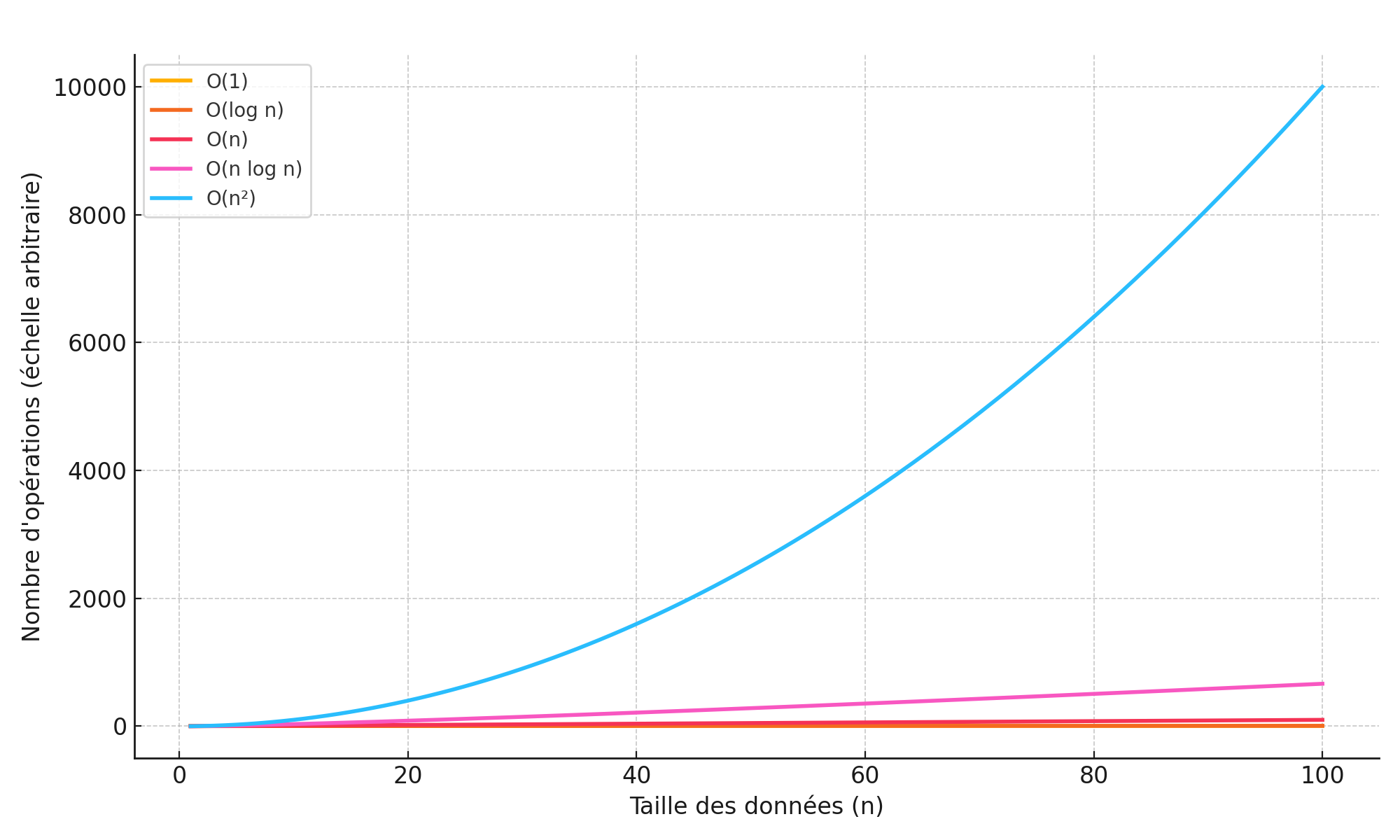
Exemple : Tri à bulles vs tri rapide
Voici deux algorithmes de tri avec leur structure en pseudo-code :
Tri à bulles (Bubble Sort) - Complexité O(n²)
pour i de 0 à n-1:
pour j de 0 à n-i-1:
si tableau[j] > tableau[j+1]:
échanger tableau[j] et tableau[j+1]
Tri rapide (Quick Sort) - Complexité O(n log n)
fonction triRapide(tableau, début, fin):
si début < fin:
pivot = partitionner(tableau, début, fin)
triRapide(tableau, début, pivot - 1)
triRapide(tableau, pivot + 1, fin)
➡️ Sur des tableaux de 10 000 éléments, le quick sort est des centaines de fois plus rapide.
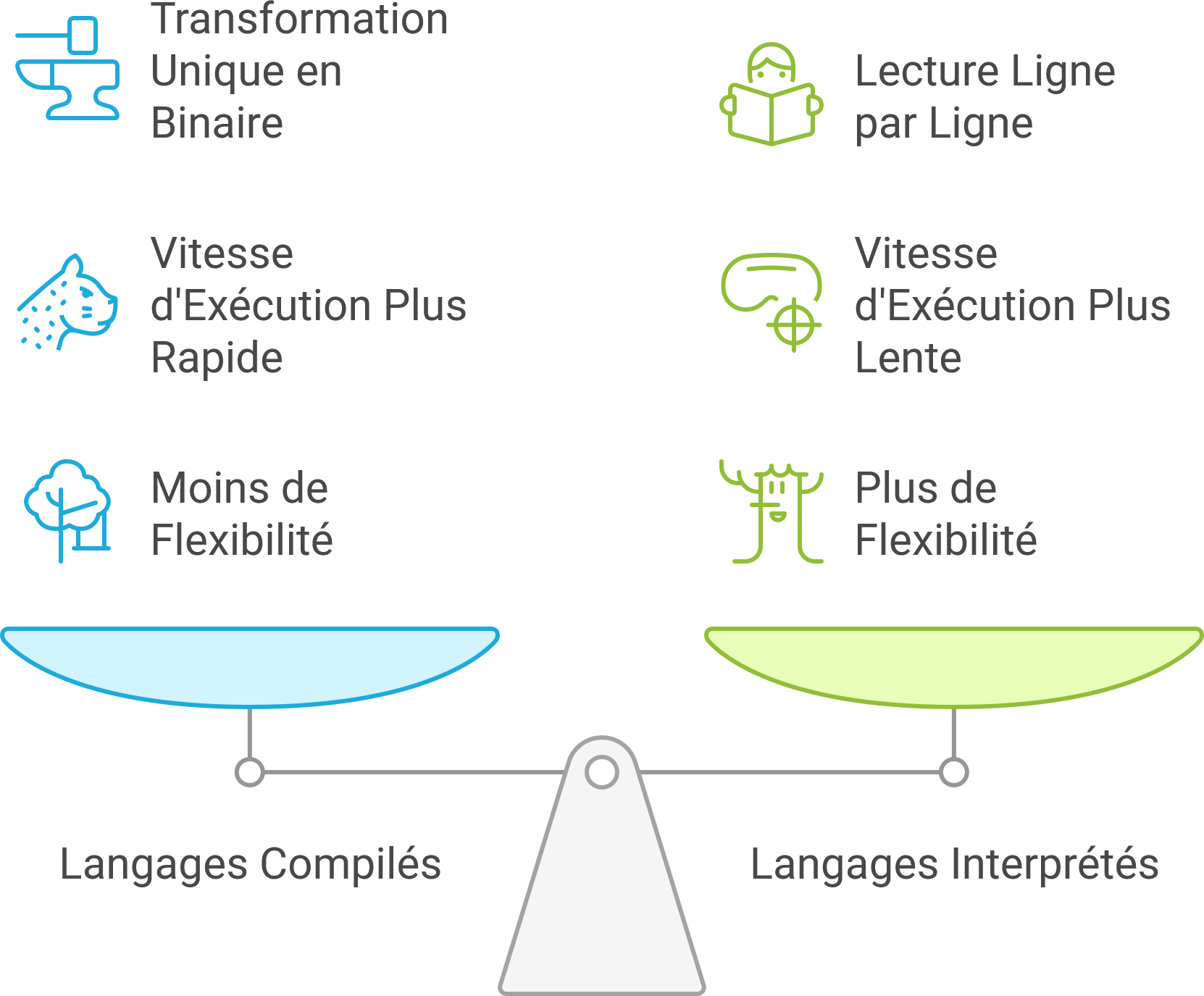
Langage : compilé vs interprété
Le langage utilisé influence directement la vitesse d’exécution.
- Langage compilé : C, C++, Rust → transformé une fois en binaire exécutable.
- Langage interprété : Python, JavaScript → lu ligne par ligne à l’exécution.
Exemple : addition de 1 à 1 million
# Python (interprété)
s = 0
for i in range(1000000):
s += i
// C++ (compilé)
long long s = 0;
for (int i = 0; i < 1000000; ++i) s += i;
➡️ Le code C++ sera exécuté plus de 50 fois plus vite.
Mais attention, les bibliothèques optimisées en Python (ex: NumPy) contiennent du code C sous-jacent, comblant ce fossé dans bien des cas.
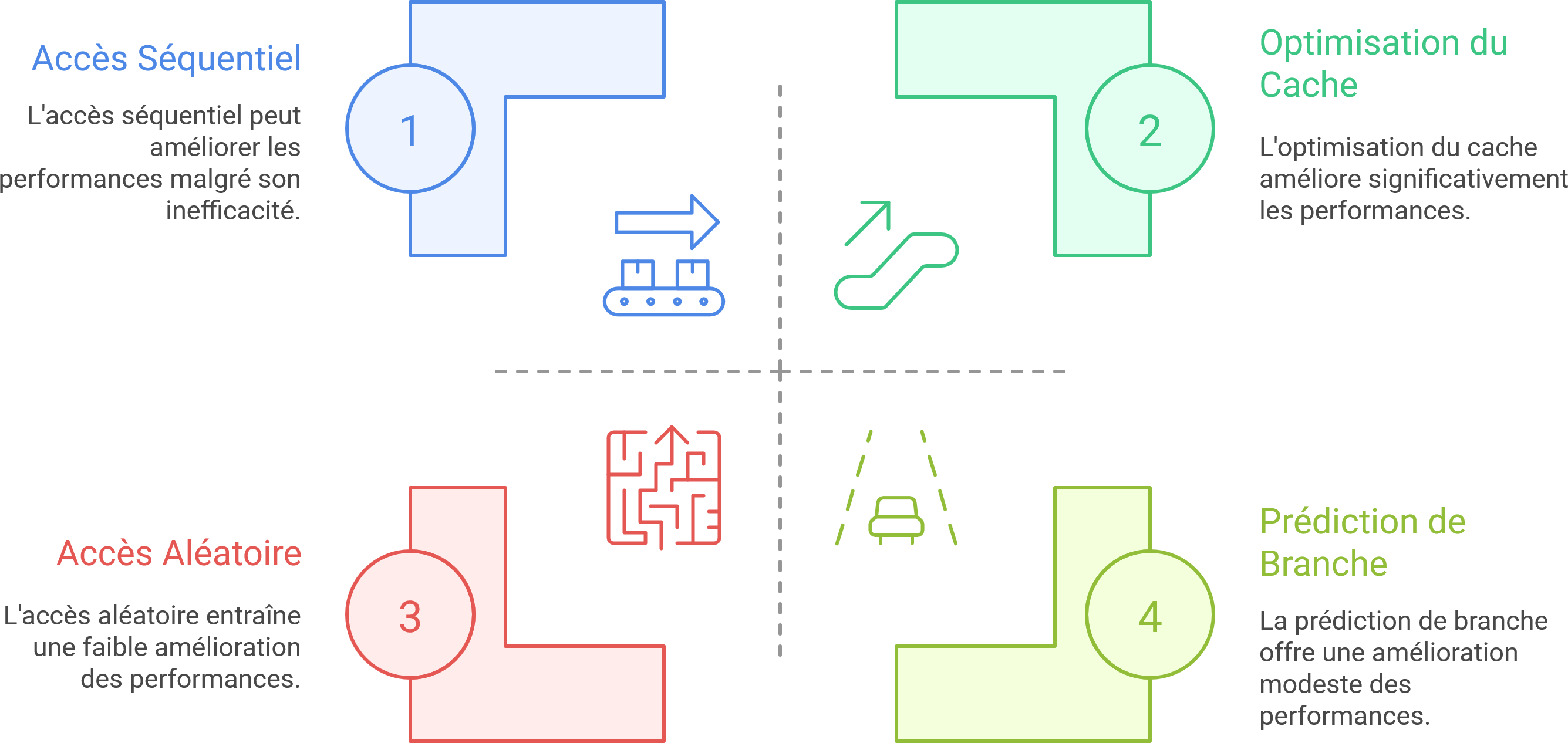
Accès mémoire : RAM, cache, disque
Les performances dépendent énormément du type d’accès mémoire :
- Cache L1 : ~1 ns
- RAM : ~100 ns
- SSD : ~100 µs (100 000 ns)
- Disque dur : ~10 ms (10 000 000 ns)
Exemple : ordre d’accès dans une matrice
# Parcours ligne par ligne (rapide)
for i in range(rows):
for j in range(cols):
total += matrix[i][j]
# Parcours colonne par colonne (lent)
for j in range(cols):
for i in range(rows):
total += matrix[i][j]
➡️ Dans la majorité des langages, le premier cas est cache-friendly (c’est-à-dire qu’il accède aux données dans l’ordre où elles sont stockées en mémoire, ce qui permet au processeur d’exploiter efficacement le cache), le second non.
Swap : quand la RAM déborde
Si votre programme utilise plus de RAM que disponible, l’OS déplace des données vers le disque (swap), rendant votre application 100x plus lente.

Parallélisation : plus de cœurs ≠ plus vite
Utiliser plusieurs cœurs peut accélérer, mais pas toujours. La loi d’Amdahl montre que le gain est limité par la portion non parallélisable.
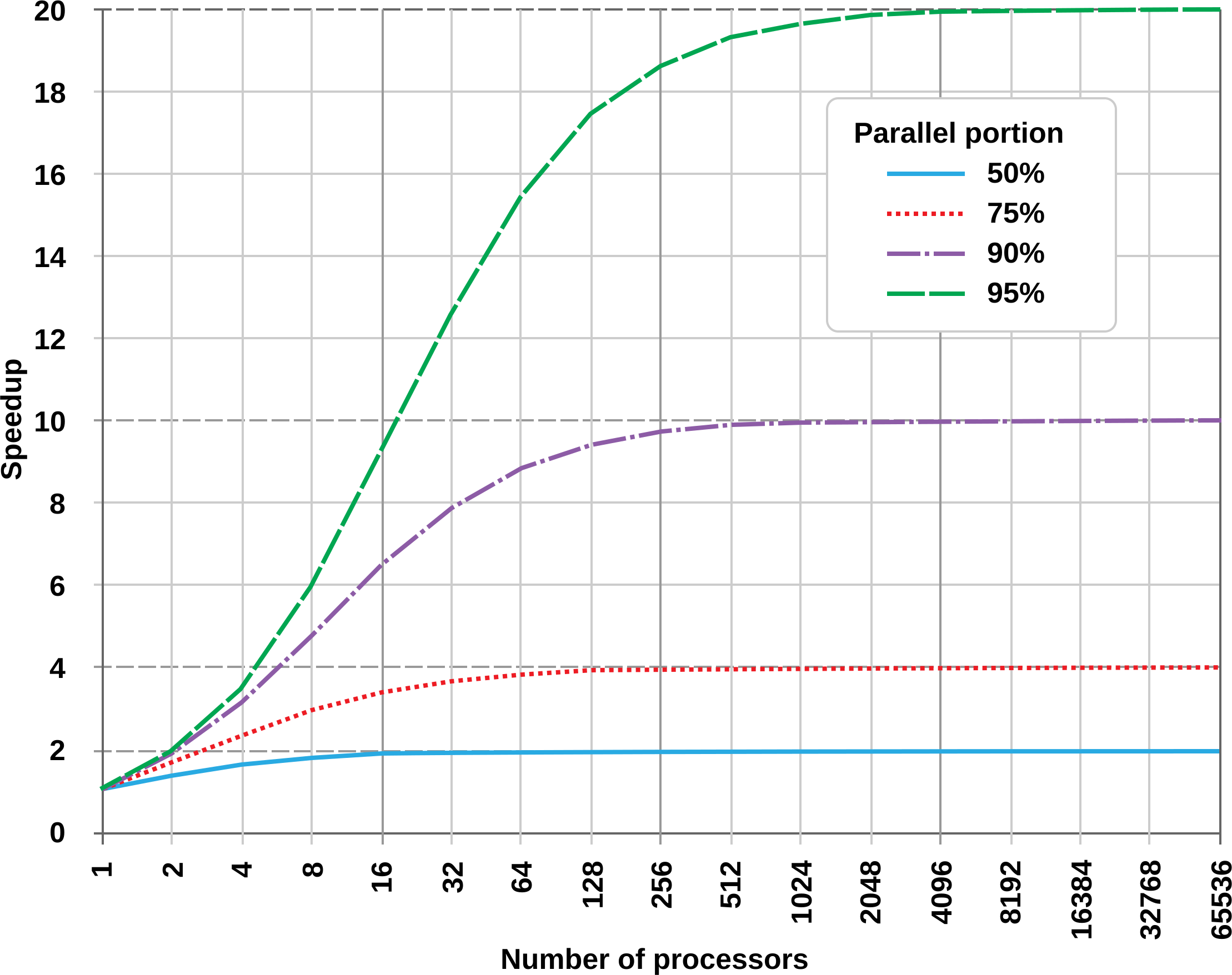
Exemple : somme d’un tableau en parallèle
// Avec std::execution en C++17
std::for_each(std::execution::par, vec.begin(), vec.end(), [](int& x){ x += 1; });
Mais si chaque thread doit accéder à une ressource partagée, le temps de synchronisation peut annuler les gains.
➡️ Moralité : parallélisez quand c’est naturellement séparable (ex: traitement d’image pixel par pixel).
Calcul GPU : des muscles, mais peu de souplesse
Les GPU peuvent exécuter des milliers de tâches en parallèle… à condition qu’elles soient simples, identiques et indépendantes.
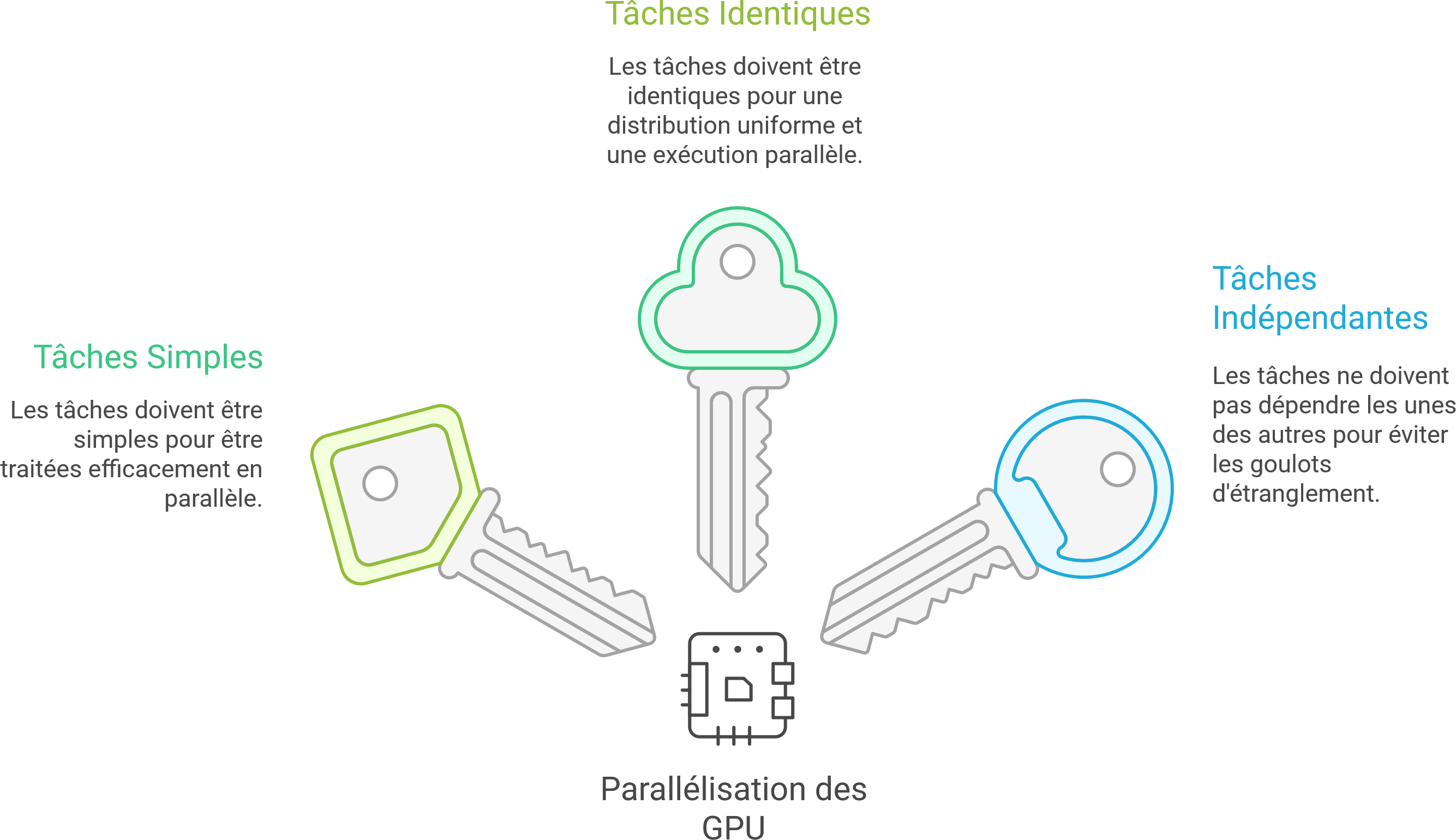
Cas efficace
- Produit de matrices massives
- Convolution pour réseau de neurones
Cas contre-productif
- Lecture d’un CSV ligne à ligne
- Arbre de décisions avec beaucoup de conditions
➡️ Transférer les données CPU → GPU a un coût. Pour des opérations simples, cela peut être plus lent que de rester sur le CPU.
Un mot sur le hardware
Le matériel reste évidemment important :
- Plus de RAM = moins de swap
- SSD vs disque dur : x100 en vitesse d’I/O
- Nombre de cœurs pour la parallélisation
Mais optimiser un programme, c’est d’abord comprendre le problème et le profil d’exécution, pas changer de machine.
Conclusion : comprendre avant d’optimiser
La performance d’un programme dépend de :
- Son algorithme
- Son langage
- Sa gestion mémoire
- Son parallélisme
- Son adaptation au matériel (ou pas)
Avant d’optimiser, il faut d’abord profiler le programme pour identifier les goulets d’étranglement. Parfois, réécrire l’algorithme est plus payant que toute autre micro-optimisation.
Pour aller plus loin
- Loi d’Amdahl
- Complexité algorithmique
- Profiler Python :
cProfile,line_profiler - Profiler C++ :
perf,gprof,valgrind
